STMIK AKAKOM YOGYAKARTA
Prodi : Rekayasa Perangkat Lunak Aplikasi
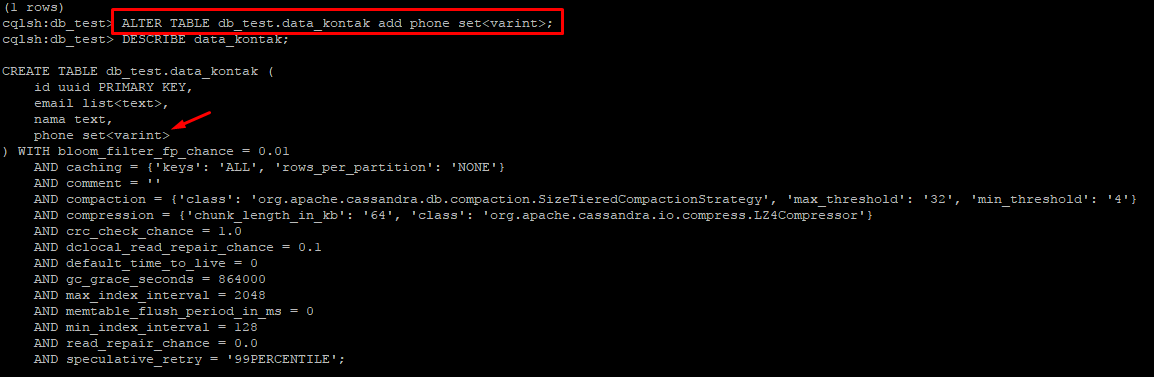
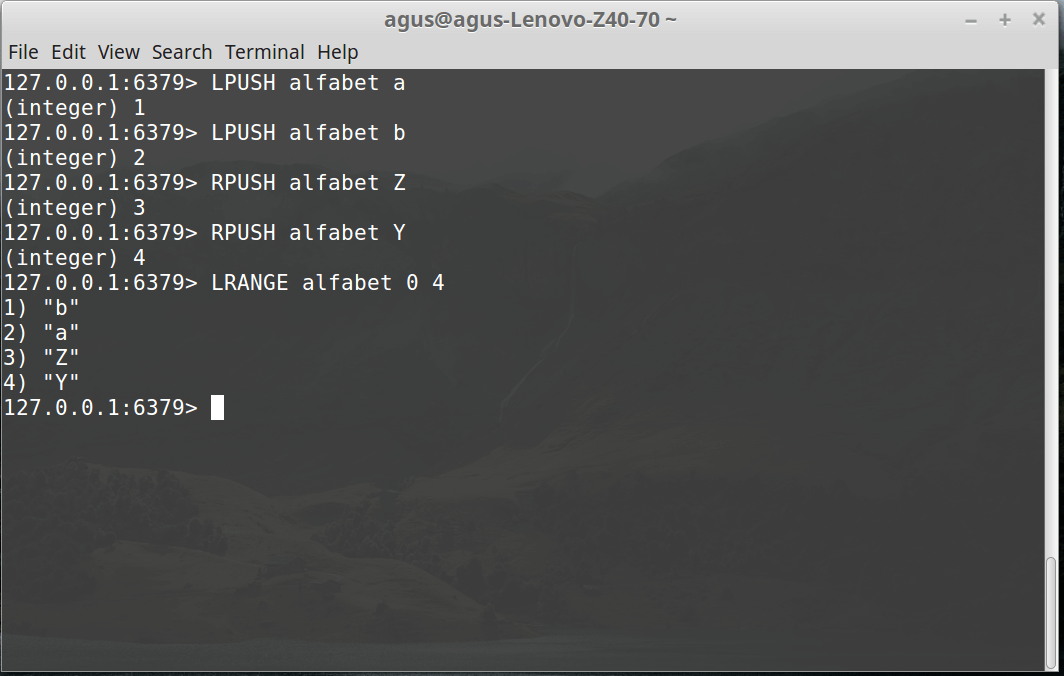
Pertama
buat database
Lalu
masukan ke dalam database yang telah di buat
Seperti
berikut :
db.inventory.insertMany ([
{ item
: "jurnal" , jumlah : 25 , size : { h : 14 , w : 21 , uom : "cm"
}, status : "A" },
{ item
: "notebook" , qty : 50 , size: { h : 8.5 , w : 11 , uom : "in"
}, status : "A" },
{ item
: "paper" , qty : 100 , size: { h : 8.5 , w : 11 , uom : "in"
}, status : "D" },
{ item
: "planner" , qty : 75 , size: { h : 22.85 , w : 30 , uom : "cm"
}, status : "D" },
{ item : "kartu pos" , jumlah : 45
, size : { h : 10 , w : 15.25 , uom : "cm" }, status : "A"
}
]);
|
Pilih Semua
Dokumen dalam Koleksi
Untuk memilih
semua dokumen dalam koleksi, berikan dokumen kosong sebagai parameter filter
kueri ke metode temukan. Parameter filter kueri menentukan kriteria pilih:
Operasi ini sesuai
dengan pernyataan SQL berikut:
Untuk informasi
lebih lanjut tentang sintaks metode, lihat find().
Tentukan Kondisi
Kesetaraan
Untuk menentukan
kondisi kesetaraan, gunakan <field>:<value>ekspresi dalam dokumen
filter kueri :
{ < field1 >: < value1 > , ... }
Contoh berikut
memilih dari inventorykumpulan semua dokumen statusdengan
jumlah yang sama "D":
db.inventory.find({ status : "D" } )
|
Operasi ini sesuai
dengan pernyataan SQL berikut:
PILIH * DARI inventory DIMANA status = "D"
|
Tentukan Kondisi
Menggunakan Operator Kueri
Sebuah dokumen
Filter permintaan dapat menggunakan operator
permintaan untuk menentukan kondisi dalam bentuk berikut:
{ < field1 >: { < operator1 >: < value1 > }, ... }
Contoh berikut
mengambil semua dokumen dari inventory
koleksi di mana status sama
dengan "A"atau "D":
db.inventory.find({status : { $ in : [ "A" , "D" ] } } )
|
Catatan
Meskipun Anda
dapat mengekspresikan kueri ini menggunakan $or operator,
gunakan $in operator
daripada $oroperator
saat melakukan pemeriksaan kesetaraan di bidang yang sama.
Lihat dokumen Operator
Kueri dan Proyeksi untuk daftar lengkap operator kueri MongoDB.
Cocokkan Dokumen
Tertanam / Bertumpuk
Untuk menentukan
kondisi kesetaraan di lapangan yang tertanam / bersarang dokumen, menggunakan dokumen penyaring permintaan mana adalah dokumen untuk
mencocokkan.
{ <field>: <value> }<value>
Misalnya, kueri
berikut memilih semua dokumen yang bidangnya sizesama dengan dokumen :{ h: 14,
w: 21, uom: "cm" }
db.inventory.find ( { size : { h : 14,w: 21,uom : "cm" }} )
|
Kecocokan kesetaraan
pada seluruh dokumen yang disematkan memerlukan kecocokan yang tepat
dari <value>
dokumen yang ditentukan , termasuk
urutan bidang. Misalnya, kueri berikut tidak cocok dengan dokumen apa pun dalam
inventorykoleksi:
db.inventory.find ( {size : { w : 21, h : 14, uom : "cm" }})
|
Query on Nested
Field
Untuk menentukan
kondisi kueri pada bidang dalam dokumen tertanam / bersarang, gunakan notasi titik ( "field.nestedField").
Catatan
Saat
menanyakan menggunakan notasi titik, bidang dan bidang bertingkat harus berada
di dalam tanda kutip.
Contoh berikut
memilih semua dokumen di mana bidang uombersarang di sizebidang sama dengan "in":
db.inventory.find ( {"size.uom" : "in" } )
|
Sebuah dokumen Filter permintaan dapat menggunakan operator permintaan untuk menentukan kondisi dalam
bentuk berikut:
{<field1>: { <operator1>: <value1>}, ... }
Kueri berikut
menggunakan kurang dari operator ( $lt) pada bidang
yang hdisematkan di sizebidang:
db.inventory.find({"size.h":{ $lt :15}} )
|
Kueri berikut
memilih semua dokumen di mana bidang bersarang hkurang dari 15, bidang bersarang uomsama dengan "in", dan statusbidang sama dengan "D":
db.inventory.find ( { "size.h"
: { $lt : 15 } )
|
Query
an Array of Embedded Documents
Halaman
ini memberikan contoh dalam:
Halaman
ini memberikan contoh operasi kueri pada array dokumen bersarang menggunakan
metode db.collection.find() di mongo shell. Contoh di halaman ini menggunakan koleksi inventory . Untuk
mengisi koleksi inventory , jalankan yang berikut:
db.inventory.insertMany( [
{item : "jurnal", instock : [ {warehouse : "A", qty : 5 },
{warehouse : "C", qty : 15 }]},
{item : "notebook", instock : [ {warehouse : "C", qty : 5 }]},
{item : "paper", instock : [ { warehouse : "A" , qty : 60 },
{warehouse : "B", qty : 15 }]},
{item : "planner", instock : [ {warehouse : "A", qty : 40},
{warehouse : "B", qty : 5 }]},
{item : "kartu pos", instock : [ {warehouse : "B", qty : 15},
{warehouse : "C", qty : 35 }]}
]);
|
Permintaan
Dokumen yang Disusun dalam Array
Contoh berikut
memilih semua dokumen di mana elemen dalam instockarray cocok dengan dokumen yang ditentukan:
db.inventory.find ( { "instock" :{ warehouse : "A" , qty : 5 } } )
|
Kecocokan
kesetaraan pada seluruh dokumen yang disematkan / disarangkan membutuhkan kecocokan
yang tepat dari dokumen yang ditentukan, termasuk urutan bidang. Misalnya,
kueri berikut tidak cocok dengan dokumen apa pun dalam inventorykoleksi:
db.inventory.find ( { "instock" : { qty : 5 , gudang : "A" } } )
|
Tentukan Kondisi
Kueri di Bidang dalam Larik Dokumen
Jika Anda tidak tahu
posisi indeks dokumen yang bersarang dalam array, gabungkan nama bidang array,
dengan titik ( .) dan nama bidang
dalam dokumen bersarang.
Contoh berikut
memilih semua dokumen di mana instock array memiliki setidaknya satu dokumen tertanam yang berisi bidang qty yang nilainya kurang dari atau sama dengan 20:
db
.inventory.find ( {'instock.qty' : { $ lte : 20} } )
|
Menggunakan notasi titik , Anda dapat menentukan kondisi kueri
untuk bidang dalam dokumen di indeks atau posisi tertentu array. Array
menggunakan pengindeksan berbasis nol.
Catatan
Saat
meminta menggunakan notasi titik, bidang dan indeks harus berada di dalam tanda
kutip.
Contoh berikut
memilih semua dokumen di mana instockarray memiliki sebagai elemen pertama dokumen yang berisi bidang qtyyang nilainya kurang dari atau sama dengan 20:
db.inventory.find ( {'instock.0.qty' : { $lte : 20 } } )
|
Tentukan Beberapa
Kondisi untuk Array Dokumen
Saat menentukan
kondisi pada lebih dari satu bidang yang bersarang di dalam array dokumen, Anda
dapat menentukan kueri sehingga satu dokumen memenuhi kondisi ini atau
kombinasi dokumen apa pun (termasuk satu dokumen) dalam array memenuhi
persyaratan.
Gunakan $elemMatchoperator
untuk menentukan beberapa kriteria pada larik dokumen yang disematkan sehingga
setidaknya satu dokumen yang disematkan memenuhi semua kriteria yang
ditentukan.
Contoh berikut
menanyakan dokumen di mana instockarray
memiliki setidaknya satu dokumen tertanam yang berisi bidang qtysama dengan 5dan bidang warehousesama dengan A:
db.inventory.find({"instock":{ $elemMatch : {qty: 5 ,gudang : "A"}}})
|
Contoh berikut ini
menanyakan dokumen di mana instockarray
memiliki setidaknya satu dokumen tertanam yang berisi bidang qtyyang lebih besar dari 10dan kurang dari atau sama dengan 20:
db.inventory.find( {"instock":{ $elemMatch :{qty:{ $gt:10, $lte:20}}}
})
|
Jika kondisi kueri
gabungan pada bidang array tidak menggunakan $elemMatch
operator, kueri memilih dokumen-dokumen yang array mengandung kombinasi elemen
yang memenuhi kondisi.
Misalnya, kueri
berikut cocok dengan dokumen di mana dokumen apa pun yang bersarang dalam instockarray memiliki qtybidang lebih besar dari 10dan dokumen apa pun (tetapi tidak harus dokumen
tertanam yang sama) dalam array memiliki qtybidang kurang dari atau sama dengan 20:
db.inventory.find ( {"instock.qty":{$ gt : 10 , $lte : 20 }})
|
Contoh berikut menanyakan
dokumen di mana instockarray
memiliki setidaknya satu dokumen tertanam yang berisi bidang qtysama dengan 5dan setidaknya satu dokumen tertanam (tetapi tidak
harus dokumen tertanam yang sama) yang berisi bidang warehousesama dengan A:
db.inventory.find({"instock.qty":5 ,"instock.warehouse":"A"})
|